データベースのデッドロックを回避する方法 |
||||||
 |
||||||
| このドキュメントでは、リレーショナル・データベースのデッドロックを特定して対処する方法について説明します。 「デッドロック」という用語は、一般に「サイクル・デッドロック」として知られる状況を指しています。具体的には、2 つ以上の競合するトランザクションが同じリソースを相互にブロックした結果 (通常、テーブルやローのロック)、どのトランザクションも処理を続行できなくなり、サーバ側でいずれかのトランザクションを強制的に終了する必要があるという状況です。 この状況に応じて、データベースのデッドロックを解決する方法として、いくつかの異なるアプローチが考えられます。それぞれのアプローチは、入手可能な情報や、対応する側の経験・嗜好に基づいています。データベース・スキーマの修正を好む管理者もいれば、SQL コードやサーバ/接続オプションの変更を優先する管理者もいるという具合です。 デッドロックの厄介な点は、テスト環境や QA 環境ではめったに発生せず、開発サイクルの早期に発見するのは困難であるということです。通常、デッドロックは高負荷の運用環境で発生します。このような環境ではデバッグは困難であり、状況によっては、コードの修正もできません。 実際にデータベースのデッドロックが発生した場合には、次の 3 つのステップで対応します。
このドキュメントの例では SQL Anywhere をデータベース・サーバとして使用していますが、基本的には、ASE、MS SQL サーバ、Oracle など、その他のリレーショナル・データベース・システム全般にも同様の技法を適用できます。 アプリケーションがデッドロックの影響を受けているかどうか確認する方法 デッドロックの発生には、規則性はないと考えられます。1 回発生して以降、まったく発生しないこともあれば、繰り返し発生することもあります。また、一定の時間帯に発生することもあれば、特定のレポート/プロシージャ・コールの処理時に発生することもあります。個々のデッドロックごとに、無視するのか注意を払うのか、対応する側で判断する必要があります。重要なポイントは、デッドロックが発生する理由は、アプリケーションとデータベース設計の領域に絞り込めるということです。 「ほとんどの時間、処理が正常に実行されているが、何も変更していないにもかかわらず、トランザクションのロールバックが発生する」「スクリプトの処理に失敗する」など、アプリケーションの動作が時折、異常になる場合や、アプリケーションから直接、次のエラーが返される場合、 SQLCODE=-306, ODBC 3 State="40001" 簡単な分析を実行し、データベースのデッドロックを引き起こしている原因を検証します。 デッドロック情報のロギング - バージョン 10、11 バージョン 9.0.2 から、ASA にデッドロック・ロギング機能が追加されています。この機能を使用すると、デッドロックを解決する上で必要な情報を入手できます。デッドロック・ロギング機能は、デフォルトでは有効になっていません。この機能を有効にするには、管理者がSybase Central または dbisql を使用して設定する必要があります。デッドロック・ロギング機能に加えて、デッドロックの発生時に実行されていた SQL 文を確認するため、ユーザ側でデータベース・オプション RememberLastStatement を有効にする必要もあります。 必要なオプションを有効にするため、dbisql から次のコマンドを実行します。
必要なオプションの設定後、再起動が発生するか、手動で消去されるまで、すべての情報はサーバによって一時的にメモリに格納されます。 デッドロックの例 デッドロック情報をそのまま入手するには、次の例を参考にしてください。dbisql ウィンドウを 2 つ開いて (Connection 1 と Connection 2)、demo11 データベースに接続します。Connection 1 から、次のコマンドを実行します。deadlock_example テーブルと、このテーブルに対する update と select を実行する 2 つのプロシージャが作成されます。
実際の環境と同様に、この例では、デッドロックがタイミング依存のイベントに該当する度合いを示しています。WAITFOR DELAY の呼び出しでは、deadlock_example ローがロックされている間にデータベース上で長時間実行されるトランザクションをシミュレートしています。次に、Connection 1 から次のコマンドを実行します。
このコマンドの実行後 (10 秒経過する前に)、Connection 2 から次のコマンドを実行します。
proc2() の実行直後にエラーが発生し、[Show Details] をクリックすると、デッドロックが検出されたことを通知する、次のメッセージが表示されます。 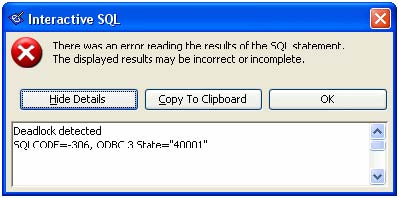 デッドロック情報の分析 SQL Anywhere には、デッドロック情報を表示するsa_report_deadlocks() というシステム・ストアド・プロシージャが用意されています。dbisql call の出力例
snapshotId,snapshotAt,waiter,who,what,object_id,record_id,owner,is_victim,rollback_operation_count 1,'2010-04-15 10:48:21.171',4,'DBA','call proc2()',3420,47906818,3,false,1 1,'2010-04-15 10:48:21.171',3,'DBA','call proc1()',3420,47906819,4,true,1 バージョン 11 では、sa_report_deadlocks() 以外にも、Sybase Central のわかりやすいビジュアル・インタフェースで、デッドロック情報を確認できます。具体的には、データベース・アイコンをクリックし、右側の [Deadlocks] タブを選択します。 バージョン 11 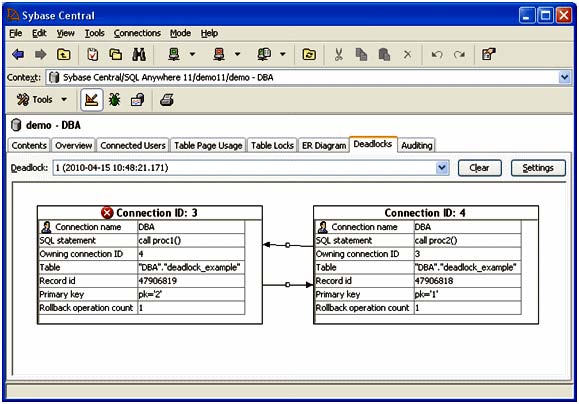 デッドロックの定義に従えば、デッドロックが発生する場合、少なくとも 2 つの異なるトランザクションが関係していることになります。デッドロックが発生する可能性は、トランザクションの所用時間と、関係するテーブル数 (ロック数) に比例して増加します。言い換えると、デッドロックを回避するには、トランザクションの所用時間を短縮すると同時に、トランザクションの処理時にアクセスの対象となるテーブル/ロック数を削減することが重要になります。トランザクションの実行に時間を要するのは、クエリの記述やインデックスに問題がある場合がほとんどです。多くのケースで、トランザクションの所用時間を短縮すれば、パフォーマンスのボトルネックだけでなく、デッドロックも解決することになります。デッドロックを解決する方法としては、デッドロックに関係するいずれかのトランザクションのロッキング動作に変更を加えることが第一に挙げられます。この方法により、得られる結果は同じでも、ロッキングについては、異なる動作で処理されることになります。ロッキング動作を変更する場合、次のようにいくつかの方法が考えられます。
環境に応じて、適用できる解決策は異なると考えられます。SQL コードがコンパイル済みアプリケーションに埋め込まれているような状況では、スキーマを変更するしか方法がありません(例. 新しいインデックスを追加して、トランザクションの所用時間を短縮する)。システムでSQL に変更を加えても問題がない場合は、ストアド・プロシージャをそのまま書き直せば目的を達成できます。 上記の例では、WAITFOR コマンドの秒数を減らすか、アイソレーション・レベルを 0 に変更します (WITH (NOLOCK) hint を使用)。たとえば、
という例では、デッドロックが発生する可能性が低下するか、デッドロックが完全に解消されます。 まとめ データベースのデッドロックを回避するには、さまざまな手順を実行する必要があります。
重要なポイントとして、デッドロックは、低品質なデータベース設計や SQL コーディング、またはシステムに潜在するその他の問題に起因して発生する症状であることに注意してください。デッドロックの問題を解決すると、アプリケーションの安定性が向上するだけでなく、データベースの全般的なパフォーマンスも改善されます。 |
||||||
Copyright 2010 iAnywhere Solutions K.K. |